아래 참고자료는 영화 콘텐츠를 기반으로 유사도를 측정하는 방법을 잘 설명하고 있습니다. 여기서 배포된 컨텐츠를 추출하고 Movie Guide를 이용하여 컨텐츠의 유사도를 측정하여 유사도 순으로 표시되는 컨텐츠를 정리합니다.
- The Movies Dataset(https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset)
- 아카이브에서 movie_metadata.csv 파일 가져오기
- 소스 코드 실행
- 오류 발생 시 관련 패키지 설치
참조
https://www.kaggle.com/code/alsojmc/movie-recommender-systems/notebook
https://quokkas.38?category=811495
https://quokkas.39?category=811495
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
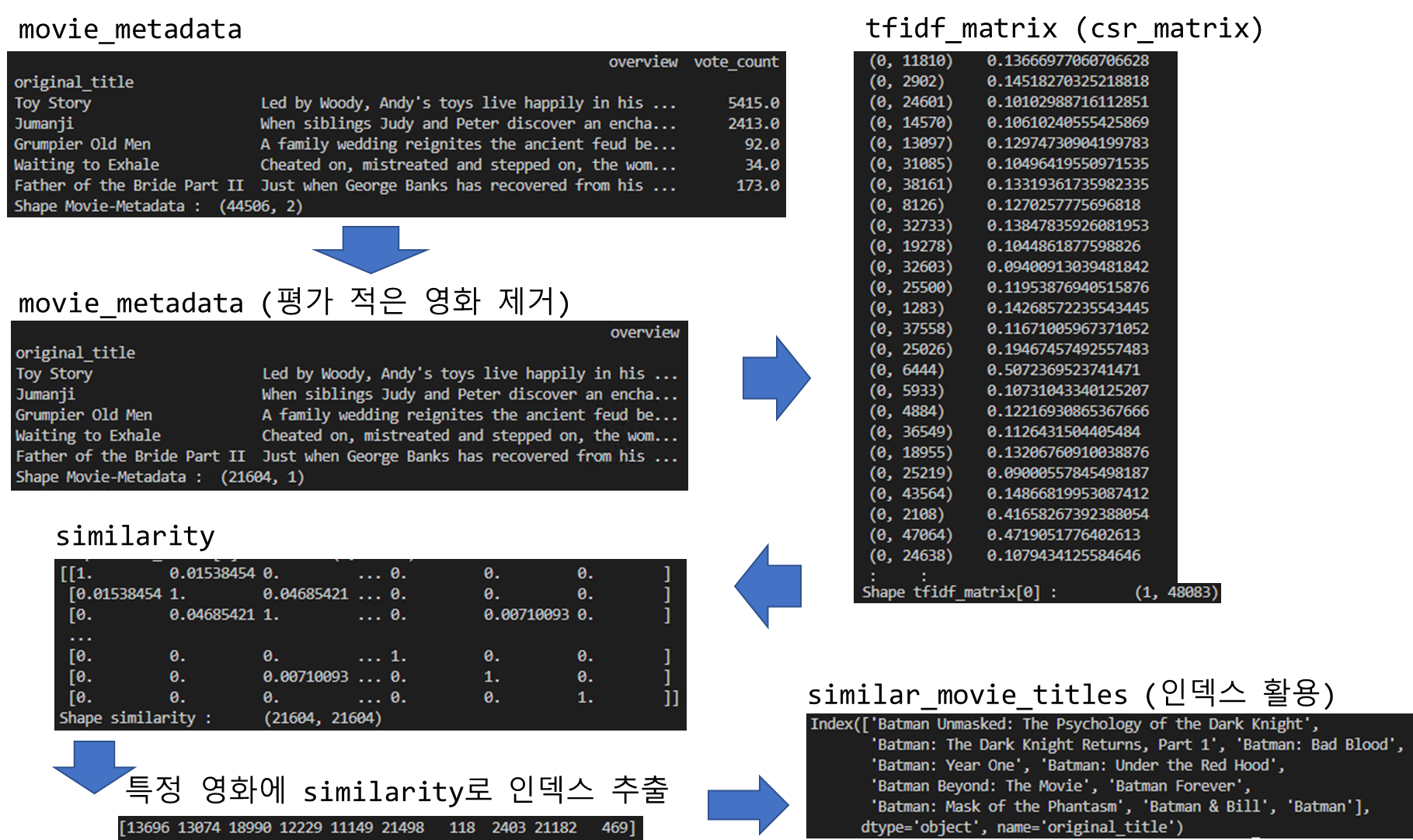
# movie metadata dataset(https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset) movies_metadata.csv 불러오기
movie_metadata = pd.read_csv('archive/movies_metadata.csv', low_memory=False)(('original_title', 'overview', 'vote_count')).set_index('original_title').dropna()
print(movie_metadata.head())
print('Shape Movie-Metadata : \t{}'.format(movie_metadata.shape))
# Remove the long tail of rarely rated movies. 평가가 적은 영화는 제거한 후 사용
movie_metadata = movie_metadata(movie_metadata('vote_count')>10).drop('vote_count', axis = 1)
print(movie_metadata.head())
print('Shape Movie-Metadata : \t{}'.format(movie_metadata.shape))
# 텍스트 비교를 위한 tf-idf 행렬 생성
tfidf = TfidfVectorizer(stop_words="english")
tfidf_matrix = tfidf.fit_transform(movie_metadata('overview').dropna())
print(tfidf_matrix)
print('Shape tfidf_matrix(0) : \t{}'.format(tfidf_matrix(0).shape))
# 영화 설명간 유사성 계산
similarity = cosine_similarity(tfidf_matrix)
print(similarity)
print('Shape similarity : \t{}'.format(similarity.shape))
# 자기 자신에 대한 유사도 제거
# 정방단위행렬((1,0,0)(0,1,0),(0,0,1))을 만들어 자기 자신과의 유사도 1을 삭제
similarity -= np.eye(similarity.shape(0))
# 유사한 영화의 인덱스 얻기 (movie_metadata은 영화이름이 인덱스, similarity 숫자가 인덱스)
movie="Batman Begins"
n_plot = 10
index = movie_metadata.reset_index(drop=True)(movie_metadata.index==movie).index(0)
# 유사 영화의 인덱스와 스코어 얻기
# (::-1) # 처음부터 끝까지 -1칸 간격으로 ( == 역순으로)
# argsort()는 Array를 정렬하는 인덱스의 Array
similar_movies_index = np.argsort(similarity(index))(::-1)(:n_plot)
similar_movies_score = np.sort(similarity(index))(::-1)(:n_plot)
print(similar_movies_index)
# 유사 영화 제목 얻기
similar_movie_titles = movie_metadata.iloc(similar_movies_index).index
print(similar_movie_titles(:10))